Using Machine Learning to Build Fair CS:GO Tournament Teams
18 Apr 2016 · 3 min read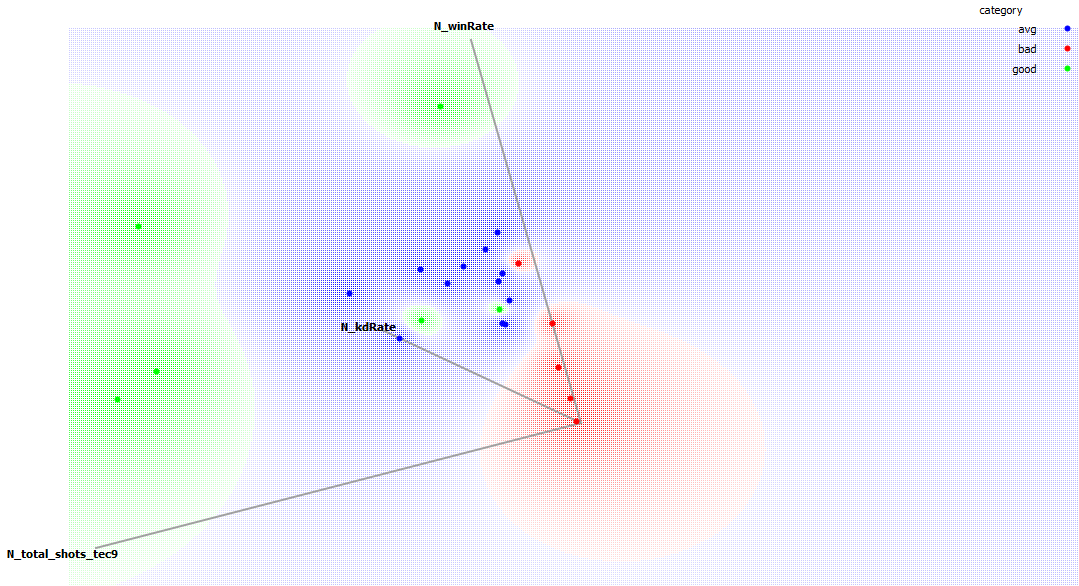 Figure: Principal Component Analysis of CS:GO Player Skill Variables
Figure: Principal Component Analysis of CS:GO Player Skill Variables
This post deviates a little from the science publication fare and is related to applied machine techiques and how they can be used in the most unusual places. Let me start first by illuminating the motivation. I am a part of the organizing body of Snooze Ry., which arranges LAN party events for youth. As you might expect, there are computer game (eSports) competitions. However, one of the issues is that the skill level of the participants varies a lot and we aim to maximise fun at the competitions. Many of the games that are played there are team-based and we try to have teams evenly matched to have the matches to be as exciting as possible. Recently we have manually assigned the best players into the different teams, but this is not a long term solution and involves a lot of manual work.
Stand Back, I am Going to Try Science
To address this issue in constructing teams for competitions a good friend of mine set out to program a more fair tournament ladder constructor. For the first test case we chose a popular first person team action game, Counterstrike: Global Offensive. The game is connected to Steam, a popular gaming platform that also records statistics and creates public profiles for players, so that we have a wealth of data available from hours played to player performance per level and the weapon of choice. This wealth of data also provided an issue: Which statistics should we use to decide the player skill? Win/lose -ratio? What if he just had good teammates? Total hours played? What if the guy is just a slow learner?
I had the bright idea to bring machine learning into the mix. Why should we decide, when we could let a machine do it? That always ends well. We chose the naive bayesian classifier for this supervised machine learning experiment (i.e. we provide enough samples to the machine and hope that it learns to classify new data from that).
Anyhow, once we were committed the system was completed pretty fast. We surveyed our friends, asked them to name good and bad players, downloaded their statistics from the Steam API and used them to show examples of good, mediocre and bad players to the machine learning algorithm. Now when the system builds teams, it does the following steps:
- Gets desired team sizes and player details as input
- Gets the Steam username for each new player and downloads stats using the Steam API
- Uses the trained classifier to label a player skilled, mediocre or unskilled
- Divides players so that each team should have as even mix of players as possible (the same average skill level for each team)
Initial Results: Player Statistics That Correlate With Our Subjective Measure of Skill
In our rather limited dataset three statistics were assigned most importance by the bayesian classifier: Total matches won in the safehouse level, win rate and total shots using the Tec9 weapon. The relationship of these is visualized in the figure below. The more points awarded, the higher chances is that the player is “good”. In our dataset it appears that a player who wins 50% of safehouse level matches, has a 100% winrate and most shots with the Tec9 weapon is an ideal “good” player. For our panel’s arbitrary definition of good, that is.
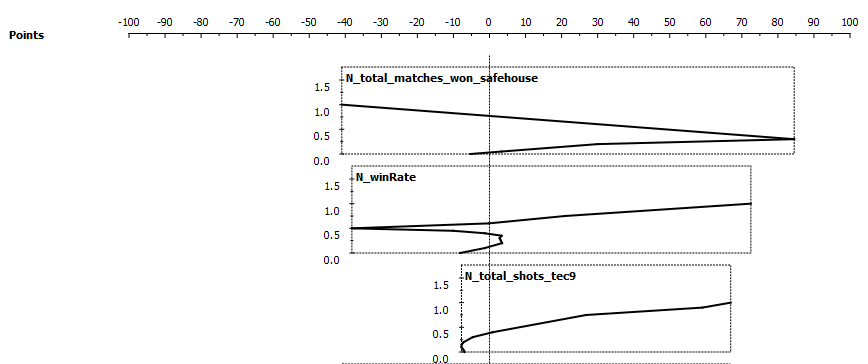 Figure: “Skill” Points Awarded by the Classifier for Three Most Important Player Statistics
Figure: “Skill” Points Awarded by the Classifier for Three Most Important Player Statistics
Wut?
Naive Bayes is a machine learning method where an algorithm uses probabilistic analysis to categorize a collection of values (e.g. measurements from some objects) to one of the predefined categories. Learn more in Wikipedia or from a Coursera course.
Also, Lappeenranta University of Technology is arranging a machine learning course under the course name CT10A7060 Advanced Topics in Software Engineering during the intensive week May 16th – 20th, 2016. If you are a student at our university, sign up using the course management system Weboodi or fire me off a message in Twitter and I’ll connect you with the lecturer.