11 Sep 2017 ·
2
min read
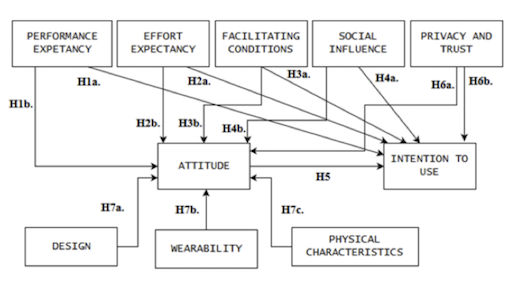 Figure: Wearables Acceptance Model
Figure: Wearables Acceptance Model
Wearable devices are in the first big peak of the hype cycle. In the article “Intended use of smartwatches and pedometers in the university environment: an empirical analysis” my collague Jayden and the rest of the team investigate what motivates people to use them. We used his prototype wearable acceptance model (WAM) and partial-least squares path modeling to find causalities in people’s views and their intention to use wearables.
In this initial study we found that the following factors affect people’s decision to use wearables:
- Performance Expectancy, or the belief that the device will help the user achieve his or her daily goals.
- Social Influence, or peer pressure.
- Privacy Concerns.
- Wearability, or how the devices can be worn. By contrast, aesthetics or other physical characteristics did not affect intention to use.
Additionally, there was an interesting non-affecting factor: Effort Expectancy. Users’ beliefs about the ease of use did not have an impact on their intention to use.
Read More
The paper is available as a preprint at ResearchGate. Full paper metadata is available at ACM Digital Library.
Continue reading
01 May 2017 ·
2
min read
 Figure: Screenshot from a Video Lecture on Gamification
Figure: Screenshot from a Video Lecture on Gamification
In this research paper we publish our results from a longitudal study where we observed ten courses that used video instruction as a part of a course. Overall the experiences with video-based learning were positive. The video lectures were perceived to be highly useful by the students and were rated to be the most useful component of the course in a majority of the observed courses. Also, some of the tutorial videos received a lot of traffic from external sources, indicating that the videos provided additional benefit to the wider public.
The problems identified from prior research, especially the added effort and costs of video production, were not not an issue. We also found that unlike in previous literature, the video length did not affect usage patterns or student satisfaction. Previously shorter videos have been recommended, but longer and well-structured videos worked just as well.
One notable statistic is that the majority of viewers used a desktop or a laptop machine (84%), while only a fraction (14%) used mobile devices such as smartphones or tables.
See also our previous work on flipped classroom teaching method, which depends heavily on video lectures (presentation slides on flipped classroom).
Read More
Preprint is available at ResearchGate.
Continue reading
11 Dec 2016 ·
3
min read
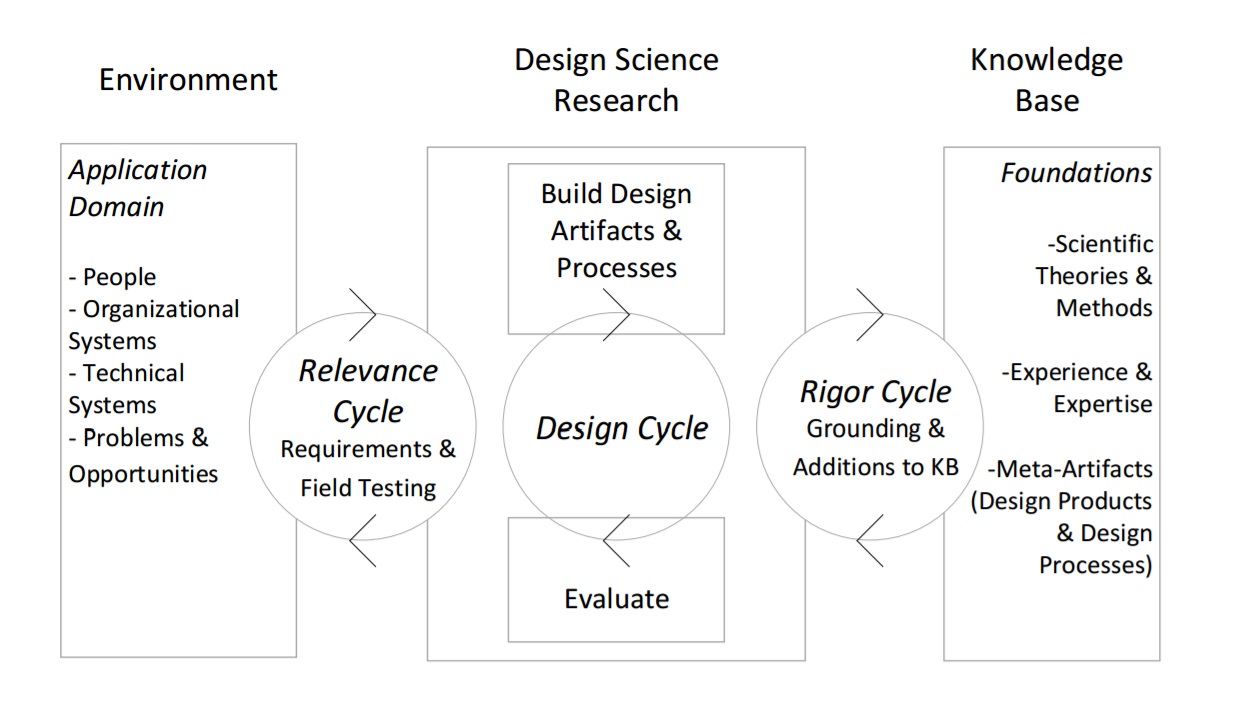 Figure: A Three Cycle view of Design Science Research Process (Hevner, 2007)
Figure: A Three Cycle view of Design Science Research Process (Hevner, 2007)
My recently defended doctoral thesis on computer-supported collaborative work is now available online. The application domain in university level engineering education, and gamification is one of the major methods I investigated and applied. The thesis also includes a rather thorough use of the design science methodology in design, implementation cycles and validation.
Read More
Find the PDF available for free from the Doria library archive.
Continue reading
24 Aug 2016 ·
3
min read
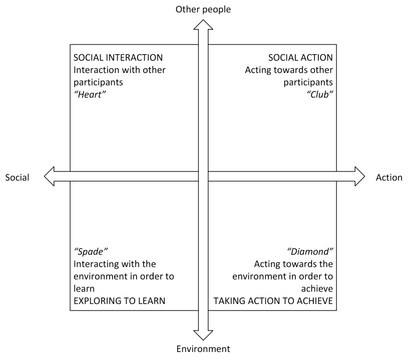 Figure: Bartle’s Taxonomy of Player Types (1996)
Figure: Bartle’s Taxonomy of Player Types (1996)
Gamification is a hot topic in research and it has been widely applied to the web. However, it is not a magic bullet for user engagement and we propose that there can be a better approach than a “one size fits all” design. Our solution is to define several different user profiles and adaptively apply them for different types of users. For example, one type of person might like having most points and being on the top of the high score and another type of user might enjoy exploring new solutions and sharing with them with the community. Both types of users might do the same activity, but their internal motivation for enjoying the activity are different. The challenge in this approach is to detect the type of user and then adaptively present the right gamification elements to each type of user.
We used an evidence-based method for deciding which gamification elements to apply and how to apply them. In order to do this we built behavior profiles with interaction analysis and profiling surveys. These profiles can be used match types of user to most suitable gamification and game design elements in order to create or improve adaptive gamification systems.
TL;DR
We discovered four types of activitiy profiles, compared them with Bartle types (2004) and matched them with formal elements of game design (Fullerton, 2008) that might be most attractive to each cluster. These profiles can be used to design adaptive gamification approaches, especially for online collaborative systems.
Read More
Read more at the IJHCITP journal website. Unfortunately this time the licensing restriction prohibited publishing a pre-print version. If your library does not subscribe to IJHCITP and you still want to view the results, please contact me on Twitter or ResearchGate and we will figure out a solution.
Continue reading
12 Jul 2016 ·
1
min read
We have published our full case study and recommendations for applying flipped classroom in teaching programming at university level. Flipped classroom is a teaching method where students first study theory by themselves as a pre-assigned homework and then learn in the classroom by working on exercises. This is the opposite of the traditional “listen at class and then work alone at home” approach, hence the term “flipped”. This approach aims to maximize the usefulness of the time the teacher and the students spend together.
To summarize, in the paper we published the following recommendations:
- Create or curate videos in addition to text-based material
- Video curating suggested, if the instructor intends to hold small lectures
- Use weekly quizzes to evaluate the level of understanding and satisfaction
- Strictly integrate the theory and material to the course
- Encourage students to engage peers in-class and to review each other’s work
- Require students to start the weekly tasks before the exercises as preparatory work
Read More
Read the conference paper in ACM Digital Library (preprint) or see the presentation slides. There’s also a poster from our previous conference presentation.
Continue reading